G3tSMuRF
G3tSmurf is primarily a database building system for indexing the smurf timestreams and ancillary smurf data to produce the tables necessary for Context and the rest of sotodlib. It also includes data loading functionality. The most general SO user will not interact much with G3tSmurf, it will build the ObsDb, ObsFileDb, and DetDb databases in the background. These will used to load data through Context. Those working closely with laboratory, level 1, or level 2 site data will likely be interacting with the databases more directly and/or using the G3tSmurf loaders.
Data Loading
Loading without Databases
We have a function that can accept any level of .g3 smurf data and load it into an AxisManager with the desired schema. These AxisManagers will not be as complete as they are when loaded with database information but will contain information available in the status frames such as the smurf band, channel mapping.
The load_file function only requires the filename or a list of file names:
aman = load_file(filename)
Loading with this method is recommended for work directly on SMuRF servers but if databases are accessible it is recommended that G3tSmurf database loads be used instead.
- sotodlib.io.load_smurf.load_file(filename, channels=None, samples=None, ignore_missing=True, no_signal=False, load_biases=True, load_primary=True, status=None, archive=None, obsfiledb=None, show_pb=True, det_axis='dets', linearize_timestamps=True, merge_det_info=True)[source]
Load data from file where there may or may not be a connected archive.
- Parameters:
filename (str or list) – A filename or list of filenames (to be loaded in order). Note that SmurfStatus is only loaded from the first file
channels (list or None) – If not None, it should be a list that can be sent to get_channel_mask.
samples (tuple or None) – If not None, it should be a tuple of (sample_start, sample_stop) where the sample counts are relative to the entire g3 session, not just the files being loaded from the list.
ignore_missing (bool) – If true, will not raise errors if a requested channel is not found
no_signal (bool) – If true, will not load the detector signal from files
load_biases (bool) – If true, will load the bias lines for each detector
load_primary (bool) – If true, loads the primary data fields, old .g3 files may not have these fields.
archive (a G3tSmurf instance (optional))
obsfiledb (a ObsFileDb instance (optional, used when loading from context))
status (a SmurfStatus Instance if we don't want to use the one from the) – first file
det_axis (name of the axis used for channels / detectors)
linearize_timestamps (bool) – sent to _get_timestamps. if true and using unix timing, linearize the timing based on the frame counter
merge_det_info (bool) – if true, emulate det_info from file info
- Returns:
aman – AxisManager with the data with axes for channels and samps. It will always have fields timestamps, signal, flags`(FlagManager), `ch_info (AxisManager with bands, channels, frequency, etc).
- Return type:
Loading with G3tSmurf
To load data with database information we first have to instantiate our G3tSmurf object. This is most easily done using a YAML configuration file because those are easily shared between people. The configuration file requires two keys:
data_prefix: "/path/to/data"
g3tsmurf_db: "/path/to/database.db"
This configuration file is set up so that other keys, such as a HWP prefixes or HK prefixes could also be added. With a config file, you connect to the G3tSmurf database as:
SMURF = G3tSmurf.from_configs("configs.yaml")
Without a configuration file, you can directly pass the required paths:
SMURF = G3tSmurf(archive_path='/path/to/data/timestreams/',
meta_path='/path/to/data/smurf/,
db_path='/path/to/database.db')
From here we can load files, time ranges, or find individual observations.
Load a file with database information for the readout channel names:
aman = load_file(filename, archive=SMURF)
Warning
The SMURF.load_data function no longer has complete functionality compared to load_file. Use load_file where possible. The example below shows how to use load_file to load a complete observation.
To find a specific Observation, a time when data was just streaming with no other specific actions being run, we can search the Observation table. Here is an example of finding the first Observation after a specific ctime:
session = SMURF.Session()
obs = session.query(Observations).filter(
Observations.timestamp > my_ctime
)
obs = obs.order_by(Observations.start).first()
aman = load_file( [f.name for f in obs.files], archive=SMURF )
These queries are built using SQLAlchemy commands and can filter on any of the columns in the Observations table.
Channel Masks on Load
Since UFMs have a large number of channels and we have many long observations it is often important to reduce active memory in some manner. One way to do that is to reduce the number of channels we load into memory at once.
All loading function accept a channels argument that is sent to the get_channel_mask function. If this argument is given, only the channels in that list will be in the returned AxisManager. The documentation for get_channel_mask includes which type of information it accepts.
- sotodlib.io.load_smurf.get_channel_mask(ch_list, status, archive=None, obsfiledb=None, ignore_missing=True)[source]
Take a list of desired channels and parse them so the different data loading functions can load them.
- Parameters:
ch_list (list) –
List of desired channels the type of each list element is used to determine what it is:
int : index of channel in file. Useful for batching.
(int, int) : band, channel
string : channel name (requires archive or obsfiledb)
float : frequency in the smurf status (or should we use channel assignment?)
status (SmurfStatus instance) – Status to use to generate channel loading mask
archive (G3tSmurf instance) – Archive used to search for channel names / frequencies
obsfiledb (ObsFileDb instance) – ObsFileDb used to search for channel names if archive is None
ignore_missing (bool) – If true, will not raise errors if a requested channel is not found
- Returns:
mask (bool array) – Mask for the channels in the SmurfStatus
TODO (When loading from name, need to check tune file in use during file.)
G3tSmurf AxisManagers
AxisManagers loaded with G3tSmurf will all have the form:
Axes:
samps -- samples in the data
dets -- channels in the data
bias_lines (optional) -- bias information
Fields:
timestamps : (samps,)
ctime timestamps for the loaded data
signal : (dets, samps)
Array of the squid phase in units of radians for each channel
primary : AxisManager (samps,)
"primary" data included in the packet headers
'AveragingResetBits', 'Counter0', 'Counter1', 'Counter2',
'FluxRampIncrement', 'FluxRampOffset', 'FrameCounter',
'TESRelaySetting', 'UnixTime'
biases (optional): (bias_lines, samps)
Bias values during the data
det_info : AxisManager (dets,)
Information about channels, including SMuRF band, channel,
frequency.
Database Creation and Upkeep
All our database building scripts are based on the file system architecture expected at the DAQ nodes. Note that this system will not work on the Smurf Servers. The system requires the folder structure to following the pattern:
/prefix/
timestreams/
16000/
stream_id1/
1600000000_000.g3
1600000000_001.g3
...
1600000000_XYZ.g3
stream_id2/
1600000000_000.g3
1600000000_001.g3
...
1600000000_XYZ.g3
16001/
stream_id1/
1600100000_000.g3
1600100000_001.g3
...
1600100000_XYZ.g3
stream_id2/
1600100000_000.g3
1600100000_001.g3
...
1600100000_XYZ.g3
...
smurf/
16000/
stream_id1/
1600000000_action1/
1600000ABC_action2/
...
1600000XYZ_actionN/
stream_id2/
1600000000_action1/
1600000ABC_action2/
...
1600000XYZ_actionN/
16001/
stream_id1/
1600100000_action1/
1600100ABC_action2/
...
1600100XYZ_actionN/
stream_id2/
1600100000_action1/
1600100ABC_action2/
...
1600100XYZ_actionN/
...
The ctimes used are just examples. But files in a specific stream_id folder will be assumed to be that stream_id. The .g3 files with the same ctime before the “_” will be assumed to be in the same observation/streaming session. The metadata searches are done through the action folders and their produced timestreams.
Database Creation and Update Script
Keeping the databases updated requires a little care when we are building databases while data is actively being taken. To assist with this there is an update_g3tsmurf_db.py script saved within the sotodlib.site_pipeline folder. This script requires config file that is the same as an expanded version of the one used for connecting to the G3tSmurf database:
data_prefix : "/path/to/daq-node/"
g3tsmurf_db: "/path/to/g3tsmurf.db"
g3thk_db: "/path/to/g3hk.db"
finalization:
servers:
- smurf-suprsync: "smurf-sync-so1" ## instance-id
timestream-suprsync: "timestream-sync-so1" ## instance-id
pysmurf-monitor: "monitor-so1" ## instance-id
- smurf-suprsync: "smurf-sync-so2" ## instance-id
timestream-suprsync: "timestream-sync-so2" ## instance-id
pysmurf-monitor: "monitor-so2" ## instance-id
The finalization information and the HK database are required for tracking the data transfer status between the level 1 servers and the level 2 DAQ node.
The user running this script must have read, write, and execute permissions to the database file in order to perform updates.
Here is the information for this script:
usage: __main__.py [-h] [--update-delay UPDATE_DELAY] [--from-scratch]
[--verbosity VERBOSITY] [--index-via-actions]
[--checked-file CHECKED_FILE] [--min_ctime MIN_CTIME]
[--max_ctime MAX_CTIME] [--profile]
[--profile-output PROFILE_OUTPUT]
config
Positional Arguments
- config
g3tsmurf db configuration file
Named Arguments
- --update-delay
Days to subtract from now to set as minimum ctime
Default:
2- --from-scratch
Builds or updates database from scratch
Default:
False- --verbosity
increase output verbosity. 0:Error, 1:Warning, 2:Info(default), 3:Debug
Default:
2- --index-via-actions
Look through action folders to create observations
Default:
False- --checked-file
Filename of file containing a list of observations that are problematic but have been manually acknowledged
- --min_ctime
minimum ctime to start search, overrides time set by update-delay
- --max_ctime
maximum ctime to search, otherwise searches through ‘now’
- --profile
Run with pyinstrument profiling
Default:
False- --profile-output
Directory to output pyinstrument profiling results to, if –profile is set
Utilities with G3tSmurf
File System Searches
Several of the generators used in the database indexing could be useful for building search functions off the same file set. G3tSmurf.search_metadata_actions and G3tSmurf.search_metadata_files are generators which can be used in loops to easily page through either actions or files. For Example:
def find_last_action(SMURF, my_action, max_ctime=None):
for action, ctime, path in SMURF.search_metadata_actions(self,
max_ctime=max_ctime, reverse = True):
if action == my_action:
return action, ctime, path
def find_last_iv(SMURF, max_ctime=None):
a, ctime, base_dir = find_last_action(SMURF, 'analyze_iv_and_save',
max_ctime=max_ctime)
files = os.listdir(os.path.join(base_dir,'outputs'))
info = [ff for ff in files if 'analyze' in ff][0]
return os.path.join(base_dir, 'outputs',info)
Operation Searches
Many types of sodetlib operations are saved in the G3tSmurf databases and we have many functions meant to be one-liner searches to help find sodetlib operations relative to observations. Note, these searches are based on automatic file tagging that was implemented in Oct. 2022. Operations from before that may not be found.
- sotodlib.io.g3tsmurf_utils.get_last_bg_map(my_obs_id, SMURF)[source]
Find the last bias group map relative to a specific observation ID.
Note: Uses a tag search that was built into sodetlib ~Oct 2022.
- sotodlib.io.g3tsmurf_utils.get_last_bias_step(my_obs_id, SMURF)[source]
Find the last bias step analysis relative to a specific observation ID.
Note: Uses a tag search that was built into sodetlib ~Oct 2022.
- sotodlib.io.g3tsmurf_utils.get_last_iv(my_obs_id, SMURF)[source]
Find the last IV analysis relative to a specific observation ID.
Note: Uses a tag search that was built into sodetlib ~Oct 2022.
- sotodlib.io.g3tsmurf_utils.get_next_bg_map(my_obs_id, SMURF)[source]
Find the next bias group map relative to a specific observation ID.
Note: Uses a tag search that was built into sodetlib ~Oct 2022.
Batched load of Observations
Loading long large observations into memory at once can cause issues with memory usage, especially on smaller computing facilities. This function is a generator than can be called to automatically split observations into smaller sections.
- sotodlib.io.g3tsmurf_utils.get_batch(obs_id, archive, ram_limit=None, n_det_chunks=None, n_samp_chunks=None, n_dets=None, n_samps=None, det_chunks=None, samp_chunks=None, test=False, load_file_args={})[source]
A Generator to loop through and load AxisManagers of sections of Observations. When run with none of the optional arguments it will default to returning the full observation. Some arguments over-write others as described in the docstrings below. When splitting the Observations by both detectors and samples, the chunks of samples for the same detectors are looped through first (samples is the inner for loop).
Example usage:
for aman in get_batch(obs_id, archive, ram_limit=2e9): run_analysis_pipeline(aman) for aman in get_batch(obs_id, archive, n_dets=200): run_analysis_pipeline(aman)
- Parameters:
obs_id (string) – Level 2 observation IDs
archive (G3tSmurf Instance) – The G3tSmurf database connected to the obs_id
ram_limit (None or float) – A (very simplistically calculated) limit on RAM per AxisManager. If specified it overrides all other inputs for how the AxisManager is split.
n_det_chunks (None or int) – number of chunks of detectors to split the observation by. Each AxisManager will have N_det = N_obs_det / n_det_chunks. If specified, it overrides n_dets and det_chunks arguments.
n_samp_chunks (None or int) – number of chunks of samples to split the observation by. Each AxisManage will have N_samps = N_obs_samps / n_samps_chunks. If specified, it overrides n_samps and samp_chunks arguments.
n_dets (None or int) – number of detectors to load per AxisManager. If specified, it overrides the det_chunks argument.
n_samps (None or int) – number of samples to load per AxisManager. If specified it overrides the samps_chunks arguments.
det_chunks (None or list of lists, tuples, or ranges) – if specified, each entry in the list is successively passed to load the AxisManagers as load_file(… channels = list[i] … )
samp_chunks (None or list of tuples) – if specified, each entry in the list is successively passed to load the AxisManagers as load_file(… samples = list[i] … )
test (bool) – If true, yields a tuple of (det_chunks, samp_chunks) instead of a loaded AxisManager
load_file_kwargs (dict) – additional arguments to pass to load_smurf
- Yields:
AxisManagers with loaded sections of data
Observation Files
There are many instances where we might want to load the SMuRF metadata associated with actions that have made it into the database. These function take an obs_id and a G3tSmurf instance and return paths or file lists.
- sotodlib.io.g3tsmurf_utils.get_obs_folder(obs_id, archive)[source]
Get the folder associated with the observation action. Assumes everything is following the standard suprsync formatting.
Usage with Context
The G3tSmurf database can be used with the larger sotodlib Context system. In this setup, the main G3tSmurf database is both the ObsFileDb and the ObsDb.
A minimal example context yaml file is:
tags:
g3tsmurf_dir: '/path/to/things/smurf_context'
obsfiledb: '{g3tsmurf_dir}/g3t_smurf_db.db'
obsdb: '{g3tsmurf_dir}/g3t_smurf_db.db'
imports:
- sotodlib.io.load_smurf
context_hooks: 'obs_detdb_load'
obs_loader_type: 'g3tsmurf'
#metadata:
SmurfStatus
SmurfStatus objects are a used to represent and parse all the data help inside the .g3 Status frames. These can be loaded from individual .g3 files using SmurfStatus.from_file(filename), this version does not require a database connection. Using a database connection we can also load the Status object based on ctime SmurfStatus.from_time(ctime, archive).
- class sotodlib.io.load_smurf.SmurfStatus(status)[source]
This is a class that attempts to extract essential information from the SMuRF status dictionary so it is more easily accessible. If the necessary information for an attribute is not present in the dictionary, the attribute will be set to None.
- Parameters:
status (dict) – A SMuRF status dictionary
- mask
Array with length
num_chansthat describes the mapping of readout channel to absolute smurf channel.- Type:
Optional[np.ndarray]
- mask_inv
Array with dimensions (NUM_BANDS, CHANS_PER_BAND) where
mask_inv[band, chan]tells you the readout channel for a given band, channel combination.- Type:
np.ndarray
- freq_map
An array of size (NUM_BANDS, CHANS_PER_BAND) that has the mapping from (band, channel) to resonator frequency. If the mapping is not present in the status dict, the array will full of np.nan.
- Type:
Optional[np.ndarray]
- filter_a
The A parameter of the readout filter.
- Type:
Optional[np.ndarray]
- filter_b
The B parameter of the readout filter.
- Type:
Optional[np.ndarray]
- flux_ramp_rate_hz
Flux Ramp Rate calculated from the RampMaxCnt and the digitizer frequency.
- Type:
- aman
- AxisManager containing the following fields:
filter_a, filter_b, filter_gain, filter_order, filter_enabled, downsample_factor, flux_ramp_rate_hz
- Type:
- classmethod from_time(time, archive, stream_id=None, show_pb=False)[source]
Generates a Smurf Status at specified unix timestamp. Loads all status frames between session start frame and specified time.
- Parameters:
time ((timestamp)) – Time at which you want the rogue status Assumed to be in UTC unless specified
archive ((G3tSmurf instance)) – The G3tSmurf archive to use to find the status
show_pb ((bool)) – Turn on or off loading progress bar
stream_id ((string)) – stream_id to look for status
- Returns:
status – object indexing of rogue variables at specified time.
- Return type:
(SmurfStatus instance)
G3tSmurf Full API
- class sotodlib.io.load_smurf.G3tSmurf(archive_path, db_path=None, meta_path=None, echo=False, db_args={}, finalize={}, hk_db_path=None, make_db=False)[source]
- classmethod from_configs(configs, **kwargs)[source]
Create a G3tSmurf instance from a configs dictionary or yaml file example configuration file will all relevant entries:
data_prefix : "/path/to/daq-node/" g3tsmurf_db: "/path/to/g3tsmurf.db" g3thk_db: "/path/to/g3hk.db" finalization: servers: - smurf-suprsync: "smurf-sync-so1" ## instance-id timestream-suprsync: "timestream-sync-so1" ## instance-id pysmurf-monitor: "monitor-so1" ## instance-id - smurf-suprsync: "smurf-sync-so2" ## instance-id timestream-suprsync: "timestream-sync-so2" ## instance-id pysmurf-monitor: "monitor-so2" ## instance-id
The HK and finalization entries in the configuration are required for maintaining the g3tsmurf database but not for simply accessing or querying information.
- Parameters:
keys (configs - dictionary containing data_prefix and g3tsmurf_db)
- add_file(path, session, overwrite=False)[source]
Indexes a single file and adds it to the sqlite database. Creates a single entry in Files and as many Frame entries as there are frames in the file.
- Parameters:
path (path) – Path of the file to index
session (SQLAlchemy session) – Current, active sqlalchemy session
overwrite (bool) – If true and file exists in the database, update it.
- index_archive(stop_at_error=False, skip_old_format=True, min_ctime=None, max_ctime=None, show_pb=True, session=None)[source]
Adds all files from an archive to the File and Frame sqlite tables. Files must be indexed before the metadata entries can be made.
- Parameters:
stop_at_error (bool) – If True, will stop if there is an error indexing a file.
skip_old_format (bool) – If True, will skip over indexing files before the name convention was changed to be ctime_###.g3.
min_ctime (int, float, or None) – If set, files with session-ids less than this ctime will be skipped.
max_ctime (int, float, or None) – If set, files with session-ids higher than this ctime will be skipped.
show_pb (bool) – If true, will show progress bar for file indexing
- delete_file(db_file, session=None, dry_run=False, my_logger=None)[source]
WARNING: Deletes data from the file system
Delete both a database file entry, it’s associated frames, AND the file itself. Only to be run by automated data management systems
- Parameters:
db_file (File instance) – database Fine instance to be deleted
session (optional, SQLAlchemy session) – should be passed if file is called as part of a larger cleanup function
dry_run (boolean) – if true, just prints deletion to my_logger.info
my_logger (logger, optional) – option to pass different logger to this function
- add_new_channel_assignment(stream_id, ctime, cha, cha_path, session)[source]
Add new entry to the Channel Assignments table. Called by the index_metadata function.
- Parameters:
stream_id (string) – The stream id for the particular SMuRF slot
ctime (int) – The ctime of the SMuRF action called to create the channel assignemnt
cha (string) – The file name of the channel assignment
cha_path (path) – The absolute path to the channel assignment
session (SQLAlchemy Session) – The active session
- add_channels_from_assignment(ch_assign, session)[source]
Add the channels that are associated with a particular channel assignment entry
- Parameters:
ch_assign (ChanAssignment instance)
session (session used to find ch_assign)
- add_new_tuning(stream_id, ctime, tune_path, session)[source]
Add new entry to the Tune table, Called by the index_metadata function.
- Parameters:
stream_id (string) – The stream id for the particular SMuRF slot
ctime (int) – The ctime of the SMuRF action called to create the tuning file.
tune_path (path) – The absolute path to the tune file
session (SQLAlchemy Session) – The active session
- add_tuneset_to_file(db_tune, db_file, session)[source]
Uses tune found in file to decide we should create a tuneset. Assigns both tune and tuneset to the file entry. called by add_file
- Parameters:
db_tune (Tunes instance for tune in file)
db_file (File instance for file)
session (sqlalchemy session used to create instances)
- add_new_observation_from_status(status, session)[source]
Wrapper to pull required information from SmurfStatus and create a new observation. Works based on tags in Status frame, so may not work with older files.
- Parameters:
status (SmurfStatus instance)
session (SQLAlchemy Session) – The active session
- add_new_observation(stream_id, action_name, action_ctime, session, calibration, session_id=None, max_early=5, status=None)[source]
Add new entry to the observation table. Called by the index_metadata function.
- Parameters:
stream_id (string) – The stream id for the particular SMuRF slot
action_ctime (int) – The ctime of the SMuRF action called to create the observation. Often slightly different than the .g3 session ID
session (SQLAlchemy Session) – The active session
calibration (boolean) – Boolean that indicates whether the observation is a calibration observation.
session_id (int (optional, but much more efficient)) – session id, if known, for timestream files that should go with the observations
max_early (int (optional)) – Buffer time to allow the g3 file to be earlier than the smurf action
status (SmurfStatus (optional)) – We’re often making observations straight from a status object so this can be used to prevent reloading that status object
- update_observation_files(obs, session, max_early=5, force=False, force_stop=False, status=None)[source]
Update existing observation. A separate function to make it easier to deal with partial data transfers. See add_new_observation for args
- Parameters:
max_early (int) – Buffer time to allow the g3 file to be earlier than the smurf action
session (SQLAlchemy Session) – The active session
force (bool) – If true, will recalculate file/tune information even if observation appears complete
force_stop (bool) – If true, will force the end of the observation to be set to the end of the current file list. Useful for completing observations where computer systems crashed/restarted during the observations so no end frames were written.
status (SmurfStatus (optional)) – We’re often making and updating observations straight from a status object so this can be used to prevent reloading that status object
- delete_observation_files(obs, session, dry_run=False, my_logger=None)[source]
WARNING: Deletes files from the file system
- Parameters:
obs (observation instance)
session (SQLAlchemy session used to query obs)
dry_run (boolean) – if true, only prints deletion to my_logger.info
- search_metadata_actions(min_ctime=1600000000.0, max_ctime=None, reverse=False)[source]
Generator used to page through smurf folder returning each action formatted for easy use.
- Parameters:
min_ctime (lowest timestamped action to return)
max_ctime (highest timestamped action to return)
reverse (if true, goes backward)
- Yields:
tuple (action, stream_id, ctime, path)
action (Smurf Action string with ctime removed for easy comparison)
stream_id (stream_id of Action)
ctime (ctime of Action folder)
path (absolute path to action folder)
- search_metadata_files(min_ctime=1600000000.0, max_ctime=None, reverse=False, skip_plots=True, skip_configs=True)[source]
Generator used to page through smurf folder returning each file formatted for easy use.
- Parameters:
min_ctime (int or float) – Lowest timestamped action to return
max_ctime (int or float) – highest timestamped action to return
reverse (bool) – if true, goes backward
skip_plots (bool) – if true, skips all the plots folders because we probably don’t want to look through them
skip_configs (bool) – if true, skips all the config folders because we probably don’t want to look through them
- Yields:
tuple (fname, stream_id, ctime, abs_path)
fname (string) – file name with ctime removed
stream_id (string) – stream_id where the file is saved
ctime (int) – file ctime
abs_path (string) – absolute path to file
- search_suprsync_files(min_ctime=1600000000.0, max_ctime=None, reverse=False)[source]
Generator used to page through smurf folder returning each suprsync finalization file formatted for easy use
- Parameters:
min_ctime (lowest timestamped action to return)
max_ctime (highest timestamped action to return)
reverse (if true, goes backward)
- Yields:
tuple (action, stream_id, ctime, path)
action (Smurf Action string with ctime removed for easy comparison)
stream_id (stream_id of Action)
ctime (ctime of Action folder)
path (absolute path to action folder)
- index_timecodes(session=None, min_ctime=1600000000.0, max_ctime=None)[source]
Index the timecode finalizeation files coming out of suprsync
- update_finalization(update_time, session=None, load_data=False)[source]
Update the finalization time rows in the database
If load_data is false then use the maximum update time in database. otherwise load the data directly to check the update time.
- get_final_time(stream_ids, start=None, stop=None, check_control=True, session=None)[source]
Return the ctime to which database is finalized for a set of stream_ids between ctimes start and stop. If check_control is True it will use the pysmurf-monitor entries in the HK database to determine which pysmurf-monitors were in control of which stream_ids between start and stop.
- index_channel_assignments(session, min_ctime=1600000000.0, max_ctime=None, pattern='channel_assignment', stop_at_error=False)[source]
Index all channel assignments newer than a minimum ctime
- index_tunes(session, min_ctime=1600000000.0, max_ctime=None, pattern='tune.npy', stop_at_error=False)[source]
Index all tune files newer than a minimum ctime
- index_observations(session, min_ctime=1600000000.0, max_ctime=None, stop_at_error=False)[source]
Index all observations newer than a minimum ctime. Uses SMURF_ACTIONS to define which actions are observations.
- index_metadata(min_ctime=1600000000.0, max_ctime=None, stop_at_error=False, session=None)[source]
Adds all channel assignments, tunes, and observations in archive to database. Adding relevant entries to Files as well.
- index_action_observations(min_ctime=1600000000.0, max_ctime=None, stop_at_error=False, session=None)[source]
Looks through Action folders to build Observations not built off of tags in add_file. This function is a hold-over from when tags were not used to find Observations (change made ~Jan. 2023)
- find_missing_files(timecode, session=None)[source]
create a list of files in the timecode folder that are not in the g3tsmurf database
- Parameters:
(int) (timecode)
- Returns:
missing (list)
- Return type:
list of file paths that are not in the g3tsmurf database
- find_missing_files_from_obs(timecode, session=None)[source]
create a list of files in the g3tsmurf database that do not have an assigned level 2 observation ID
- Parameters:
(int) (timecode)
- Returns:
missing (list)
- Return type:
list of file paths that do not have level 2 observation IDs
- lookup_file(filename, fail_ok=False)[source]
Lookup a file’s observations details in database. Meant to look and act like core.metadata.obsfiledb.lookup_file.
- load_data(start, end, stream_id=None, channels=None, show_pb=True, load_biases=True, status=None)[source]
Loads smurf G3 data for a given time range. For the specified time range this will return a chunk of data that includes that time range.
This function returns an AxisManager with the following properties:
* Axes: * samps : samples * dets : resonator channels reading out * bias_lines (optional) : bias lines * Fields: * timestamps : (samps,) unix timestamps for loaded data * signal : (dets, samps) Array of the squid phase in units of radians for each channel * primary : AxisManager (samps,) "primary" data included in the packet headers 'AveragingResetBits', 'Counter0', 'Counter1', 'Counter2', 'FluxRampIncrement', 'FluxRampOffset', 'FrameCounter', 'TESRelaySetting', 'UnixTime' * biases (optional): (bias_lines, samps) Bias values during the data * ch_info : AxisManager (dets,) Information about channels, including SMuRF band, channel, frequency.
- Parameters:
start (timestamp or DateTime) – start time for data, assumed to be in UTC unless specified
end (timestamp or DateTime) – end time for data, assumed to be in UTC unless specified
stream_id (String) – stream_id to load, in case there are multiple
channels (list or None) – If not None, it should be a list that can be sent to get_channel_mask.
detset (string) – the name of the detector set (tuning file) to load
show_pb (bool, optional:) – If True, will show progress bar.
load_biases (bool, optional) – If True, will return biases.
status (SmurfStatus, optional) – If note none, will use this Status on the data load
- Returns:
aman – AxisManager for the data
- Return type:
- load_status(time, stream_id=None, show_pb=False)[source]
Returns the status dict at specified unix timestamp. Loads all status frames between session start frame and specified time.
- Parameters:
time (timestamp) – Time at which you want the rogue status
- Returns:
object indexing of rogue variables at specified time.
- Return type:
status (SmurfStatus instance)
Database Tables
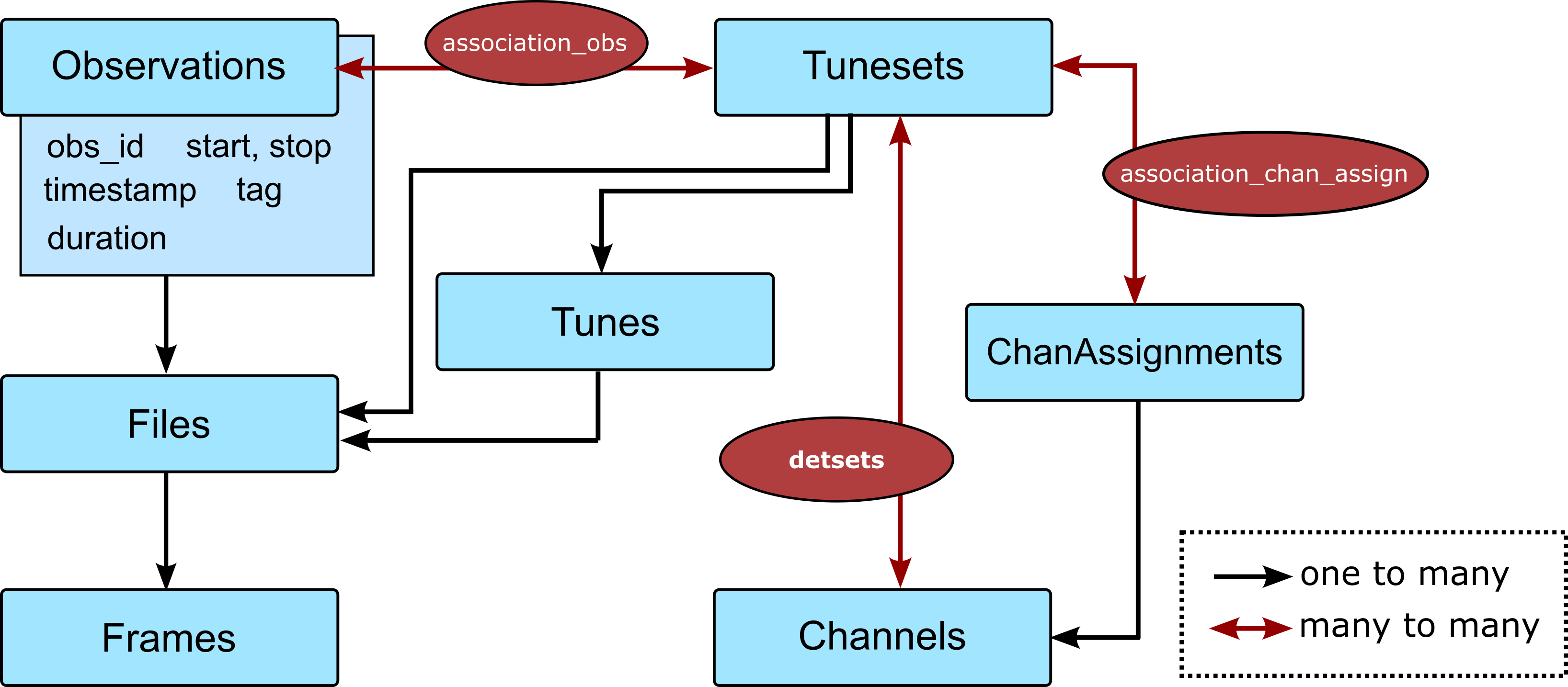
- class sotodlib.io.g3tsmurf_db.Observations(**kwargs)[source]
Times of continuous detector readout. This table is named obs and serves as the ObsDb table when loading via Context. This table is meant to by built off of Level 2 data, before the data from different stream_id/smurf slots have been bookbound and perfectly co-sampled.
Observations are not created if the action folder has no associated .g3 files.
Dec. 2021 – The definitions of obs_id and timestamp changed to better match the operation of the smurf-streamer / sodetlib / pysmurf. Oct. 2022 – The definition of obs_id changed again to include obs or oper tags based on if the observation is an sodetlib operation or not.
- obs_id
<obs|oper>_<stream_id>_<session_id>.
- Type:
string
- timestamp
The .g3 session_id, which is also the ctime the .g3 streaming started and the first part .g3 file name.
- Type:
integer
- action_ctime
The ctime of the pysmurf action, generally slightly different than the .g3 session_id
- Type:
integer
- action_name
The name of the action used to create the observation.
- Type:
stream
- stream_id
The stream_id of this observation. Generally corresponds to UFM or Smurf slot. Column is implemented since level 2 data is not perfectly co-sampled across stream_ids.
- Type:
string
- timing
If true, the files of the entry observation were made with times aligned to the external timing system and high precision timestamps.
- Type:
- n_samples
The total number of samples in the observation
- Type:
integer
- start
The start of the observation as a datetime object
- Type:
- stop
The end of the observation as a datetime object
- Type:
- tag
Tags for this observation in a single comma delimited string. These are populated through tags set while running sodetlib’s stream data functions.
- Type:
string
- calibration
Boolean that stores whether or not the observation is a calibration-type observation i.e. an IV curve, a bias step, etc.
- Type:
- files
The list of .g3 files in this observation built through a relationship to the Files table. [f.name for f in Observation.files] will return absolute paths to all the files.
- class sotodlib.io.g3tsmurf_db.Tunes(**kwargs)[source]
Indexing of ‘tunes’ available during observations. Should correspond to all tune files.
- id
primary key
- Type:
integer
- name
name of tune file
- Type:
string
- path
absolute path of tune file
- Type:
string
- stream_id
stream_id for file
- Type:
string
- start
The time the tune file is made
- Type:
- tuneset_id
id of tuneset this tune belongs to. Used to link Tunes table to TuneSets table
- Type:
integer
- tuneset
- Type:
SQLAlchemy TuneSet instance
- class sotodlib.io.g3tsmurf_db.TuneSets(**kwargs)[source]
Indexing of ‘tunes sets’ available during observations. Should correspond to the tune files where new_master_assignment=True. TuneSets exist to combine sets of <=8 Channel Assignments since SMuRF tuning and setup is run “per smurf band” while channel readout reads all tuned bands. Every TuneSet is a Tune file but not all Tunes are a Tuneset. This is because new Tunes can be made for the same set of channel assignments as the cryostat / readout environments evolve.
- id
primary key
- Type:
integer
- name
name of tune file
- Type:
string
- path
absolute path of tune file
- Type:
string
- stream_id
stream_id for file
- Type:
string
- start
The time the tune file is made
- Type:
- stop
Not Implemented Yet
- Type:
datetime.datetine
- class sotodlib.io.g3tsmurf_db.ChanAssignments(**kwargs)[source]
The available channel assignments. TuneSets are made of up to eight of these assignments.
- id
primary key
- Type:
integer
- ctime
ctime where the channel assignment was made
- Type:
integer
- name
name of the channel assignment file
- Type:
string
- path
absolute path of channel assignment file
- Type:
string
- stream_id
stream_id for file
- Type:
string
- band
Smurf band for this channel assignment
- Type:
integer
- class sotodlib.io.g3tsmurf_db.Channels(**kwargs)[source]
All the channels tracked by SMuRF indexed by the ctime of the channel assignment file, SMuRF band and channel number. Many channels will map to one detector on a UFM.
Dec. 2021 – Updated channel names to include stream_id to ensure uniqueness
- id
primary key
- Type:
integer
- name
name of of channel. This is the unique readout id that will be matched with the unique detector id. Has the form of sch_<stream_id>_<ctime>_<band>_<channel>
- Type:
string
- stream_id
stream_id for file
- Type:
string
- subband
The subband of the channel
- Type:
integer
- channel
The assigned smurf channel
- Type:
integer
- band
The smurf band for the channel
- Type:
integer
- ca_id
The id of the channel assignment for the channel. Used for SQL mapping
- Type:
integer
- chan_assignment
- Type:
SQLAlchemy ChanAssignments Instance
- detsets
The tunesets the channel can be found in
- Type:
List of SQLAlchemy Tunesets
- class sotodlib.io.g3tsmurf_db.Files(**kwargs)[source]
Table to store file indexing info. This table is named files in sql and serves as the ObsFileDb when loading via Context.
- id
auto-incremented primary key
- Type:
integer
- name
complete absolute path to file
- Type:
string
- start
the start time for the file
- Type:
- stop
the stop time for the file
- Type:
- sample_start
Not Implemented Yet
- Type:
integer
- sample_stop
Not Implemented Yet
- Type:
integer
- obs_id
observation id linking Files table to the Observation table
- Type:
String
- observation
- Type:
SQLAlchemy Observation Instance
- stream_id
These are expected to map one per UXM.
- Type:
The stream_id for the file. Generally of the form crateXslotY.
- timing
If true, every frame in the file has high precision timestamps (slightly different definition than obs.timing)
- Type:
- n_frames
Number of frames in the .g3 file
- Type:
Integer
- frames
List of database entries for the frames in this file
- Type:
list of SQLALchemy Frame Instances
- n_channels
The number of channels read out in this file
- Type:
Integer
- detset
TuneSet.name for this file. Used to map the TuneSet table to the Files table. Called detset to serve duel-purpose and map files to detsets while loading through Context.
- Type:
string
- tuneset
- Type:
SQLAlchemy TuneSet Instance
- tune_id
id of the tune file used in this file. Used to map Tune table to the Files table.
- Type:
integer
- tune
- Type:
SQLAlchemy Tune Instance
- class sotodlib.io.g3tsmurf_db.Frames(**kwargs)[source]
Table to store frame indexing info .. attribute:: id
Primary Key
- type:
Integer
- file_id
id of the file the frame is part of, used for SQL mapping
- Type:
integer
- file
- Type:
SQLAlchemy instance
- frame_idx
frame index in the file
- Type:
integer
- offset
frame offset used by so3g indexed reader
- Type:
integer
- type_name
frame types, use Observation, Wiring, and Scan frames
- Type:
string
- time
The start of the frame
- Type:
- n_samples
the number of samples in the frame
- Type:
integer
- n_channels
the number of channels in the frame
- Type:
integer
- start
the start of the frame
- Type:
- stop
the end of the frame
- Type: